
Mastering the Coding Interview: 3 Essential Algorithms for Search


There are many possible interview questions. Here we will see some algorithms to solve some possible problems we can have during an interview or work.
1. Binary Search
Binary Search can be used to provide better performance in searching an element in a sorted array.
In case you have a sorted array and want to find an element, the binary search can be a suitable option.
Problem: Finding a Book in a Sorted Library
Imagine you are in a large library where the books are arranged in alphabetical order by their titles. You are looking for a specific book, and you know its title.
You want to find the book efficiently without checking each book one by one. This is where Binary Search can be applied.
Solution with Java
public static void main(String[] args) {
Book[] books = {new Book("1", "Clean code"),
new Book("2", "Clean coder"),
new Book("3", "Don Quixote"),
new Book("4", "Hamlet"),
new Book("5", "Lord of the Rings")
};
String targetElement = "Hamlet";
int result = binarySearch(books, targetElement);
// Displaying the result
if (result != -1) {
System.out.println("Book found ISBN: " + books[result]);
} else {
System.out.println("Book not found in the library.");
}
}
// Binary Search algorithm
private static int binarySearch(Book[] books, String target) {
int left = 0; //first
int right = books.length - 1; //last
while (left != right) {
int mid = left + (right - left) / 2;
int comparison = target.compareTo(books[mid].title);
if (comparison == 0) {
return mid;
}
if (comparison < 0) {
right = mid - 1;
} else {
left = mid + 1;
}
}
return -1;
}
record Book(String isbn, String title) {}
This is one of many ways to search for elements. Using Binary Search, we have a time complexity of O (log n). However, there are other kinds of sorts, like hashing, Jump Search, Exponential Search, and much more. Let’s see another kind of Search algorithm.
2. Hash Search
The Hash is used in many data structures and can be used to solve many problems efficiently.
A hash function is applied to each word to compute a hash code.
The hash code is used to determine the index (or bucket) in the hash table.
The hash table stores key-value pairs, where keys are unique words, and values are the frequencies.
Problem: Finding the 3 most used words in a text
Imagine you are working on a social media analytics platform that analyses user comments on posts. Your platform receives a large volume of comments daily, and you want to extract insights from the user-generated content.
You need to identify the most 3 used words in the comments.
Solution with Java
public static void main(String[] args) {
List<String> comments = List.of(
"Great post! Really informative.",
"I totally agree with your points.",
"This is awesome!",
"Nice work. Keep it up!",
"Great insights. Thanks for sharing.",
"I love it, it is awesome.",
"Great "
);
Map<String, Integer> wordFrequencies = analyzeWordFrequencies(comments);
displayTopWords(wordFrequencies, 3);
}
private static Map<String, Integer> analyzeWordFrequencies(List<String> comments) {
return comments
.stream()
.flatMap(c -> Arrays.stream(c.split("[\\s.,;!?]+")))
.filter(w -> w.length() > 2)
.collect(Collectors.groupingBy(m -> m,
Collectors.summingInt(m -> +1)));
}
private static void displayTopWords(Map<String, Integer> wordFrequencies, int topN) {
wordFrequencies.entrySet()
.stream()
.sorted((entry1, entry2) -> entry2.getValue().compareTo(entry1.getValue()))
.limit(topN)
.forEach(e -> System.out.println(e.getKey() + ": " + e.getValue() + " occurrences"));
}
The operation of analyzeWordFrequencies has a time complexity O(L⋅M), where L is the number of comments and M is the average number of words in a comment.
And the operation of displayTopWords has a time complexity O(K log K) for the sorting operation, where K is the number of unique words, and O(N) for the limit operation, where N is the topN variable.
The overall time complexity is O(L⋅M+KlogK+N), where L is the number of comments, M is the average number of words in a comment, K is the number of unique words and N is the limit of the result.
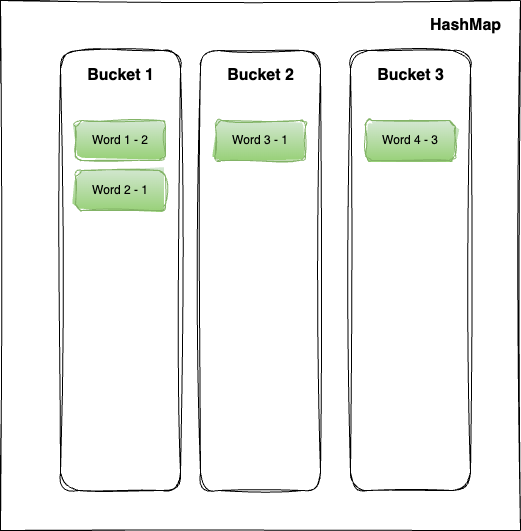
Dealing with Hash data structure, we should be aware of Collisions, that happens when two words produce the same hash code (a collision).
Collision resolution strategies are employed to handle this. Common strategies include chaining or open addressing.
In the case of Java, using the HashMap is an efficient way to deal with hash collisions, which implements the chaining mechanism.
In Java's HashMap, each bucket in the hash table can store multiple entries. When a hash collision occurs (two different words hash to the same index), the entries are stored as a linked list in that bucket. This linked list is referred to as a "chain."
When a new entry is added to a bucket with an existing chain (collision), the HashMap appends the new entry to the linked list. This ensures that all entries with the same hash code are stored in the same bucket.
3. Sliding Window
A sliding window is a technique used in array/string problems where you maintain a set of elements as you iterate through the array or string. The set typically represents a contiguous subarray or substring, and the window "slides" or moves one element at a time.
This approach is particularly useful for efficiently solving problems involving substrings or subarrays, especially those with constraints like a specific size or sum.
Problem: Finding the longest Substring Without Repeating Characters
Given a string, find the length of the longest substring without repeating characters.
Solution with Java
public static void main(String[] args) {
String s1 = "abcabcbb";
System.out.println("Length of Longest Substring (s1): " + lengthOfLongestSubstring(s1));
}
public static int lengthOfLongestSubstring(String s) {
int maxLength = 0;
int left = 0;
int right = 0;
Set<Character> uniqueCharacters = new HashSet<>();
while (right < s.length()) {
if (!uniqueCharacters.contains(s.charAt(right))) {
uniqueCharacters.add(s.charAt(right));
maxLength = Math.max(maxLength, right - left + 1);
right++;
} else {
uniqueCharacters.remove(s.charAt(left));
left++;
}
}
return maxLength;
}
In this problem, the sliding window approach is used to find the length of the longest substring without repeating characters. The left and right pointers define the current window, and a HashSet (uniqueCharacters) is used to keep track of characters within the window.
The time complexity of this solution is O(N), where N is the length of the input string. The sliding window efficiently slides through the string while maintaining the longest substring without repeating characters.
Conclusion
There are many algorithms to solve different problems. Knowing them is essential to provide the best solution, providing the best performance, and a more legible code.
References
Cracking the Coding Interview: 189 Programming Questions and Solutions